Data Mart
What it is, why it matters, and best practices. This guide provides a data mart definition and practical advice to help you understand and establish a modern data mart.
What is a Data Mart?
A data mart is a structured data repository purpose-built to support the analytical needs of a particular department, line of business, or geographic region within an enterprise. Data marts are typically created as partitioned segments of an enterprise data warehouse, with each being relevant to a specific subject or department in your organization such as finance or sales. Data marts help you perform analysis faster given that you’re working with a smaller, more applicable dataset.
Data Mart Benefits
Your organization is likely flooded by massive, complex datasets from many sources, both historical data and real-time streaming data. All this big data typically lives in a data warehouse and users have to code complex queries to get the answers they seek.
But your teams need to make data-driven decisions quickly and confidently. This is where data marts come in. They’re an efficient approach which allows analytics and business users to explore and analyze more manageable subsets of data which are directly relevant to them. Here are the key benefits:
- More trustworthy data. Data marts create a “single source of truth” regarding a certain subject or department. This gives your teams a collective view of the data and allows them to focus on finding insights, making decisions, and taking action rather than sharing spreadsheets and wondering which data is accurate.
- Easier access to data. Since data marts hold a subset of data, you can access the data you need with less effort than dealing with a cluttered data warehouse. Plus, by establishing connections to the appropriate data sources, you can access live data anytime without waiting for IT to perform periodic extracts.
- Faster insights & decisions. The focused nature of a data mart also allows you to more quickly leverage your analytics and business intelligence tools because you’re only working with a relevant, frequently needed data set.
- Lower cost. Data marts typically cost far less to set up than establishing a full data warehouse.
- Easier implementation & maintenance. Unlike data warehouses, which require integration with a wide variety of internal and external data sources, data marts only contain data essential to the particular business unit or department. This makes for faster and easier implementation and maintenance because you’re serving the needs of a specific business team rather than your entire organization.
- Better support short-term projects. As noted above, you can quickly and cost-effectively establish a data mart, so they are well-suited for short-term data analysis projects such as determining the effectiveness of an advertising campaign.
- Better data access control. Data in your mart is partitioned from the broader data warehouse. This gives you the ability to control data access privileges at a granular level.
Data Lake vs Data Warehouse vs Data Mart
The terms data lake, data warehouse, and data mart should not be used interchangeably. They each serve different needs in your organization and here we describe key differences between them.
Data mart vs data warehouse
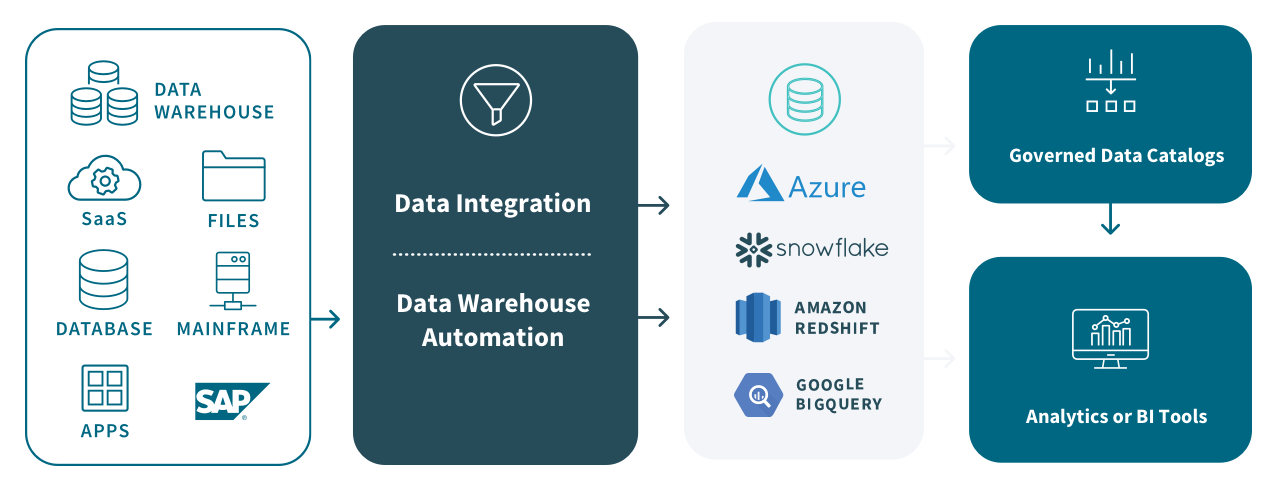
Marts and warehouses are both read-only, structured data repositories of transactional data. But they differ in the scope of data which is stored. Data warehouses aggregate large volumes of data from multiple sources such as transactional applications and application log files into a single repository of highly structured and unified historical data. Data marts consist of a subset of this warehouse data which is relevant to a specific subject or department in your organization. As shown below, they’re added between the warehouse and the analytics tools.
| FACTOR | DATA MART | DATA WAREHOUSE |
|---|---|---|
|
Type of Data
|
Summarized historical (traditionally).
|
Summarized historical (in traditional DW’s).
|
|
Data Sources
|
Fewer source systems which are operationally focused.
|
Wide variety of source systems from all across the enterprise.
|
|
Use Case/ Scope
|
Analyzing smaller data sets (typically <100 GB) focused on a particular subject to support analytics and business intelligence (BI).
|
Analyzing large (typically 100+ GB), complex, enterprise-wide datasets to support data mining, BI artificial intelligence, and machine learning.
|
|
Data governance
|
Easier because data is already partitioned.
|
Requires strict governance rules and systems to access data.
|
More resources:
- Learn more about data warehouses.
- Compare top cloud data warehouses.
Data mart vs data lake
The main difference in data mart vs data lake is the type and volume of data stored. Marts typically hold smaller amounts of structured data which has been transformed whereas data lakes consist of massive amounts of raw, unstructured data. Another key difference is that the data in marts has been selected to serve a well-defined need whereas the purpose of data in data lakes has not necessarily been defined. Many organizations use both systems to accommodate their range of storage needs.
| FACTOR | DATA MART | DATA LAKE |
|---|---|---|
|
Type of Data
|
Usually structured data which has been transformed.
|
Raw, unstructured data.
|
|
Use Case
|
Business users analyzing a narrow dataset to answer pre-determined questions on specific subject (such as marketing programs).
|
Data scientists and engineers exploring and analyzing raw data to uncover new business insights.
|
|
Analysis and output
|
BI and data analytics producing visualizations, dashboards, and reports.
|
Predictive analytics, BI, big data analytics, machine learning, and AI producing prescriptive recommendations, visualizations, dashboards, and reports.
|
|
Cost
|
Lower cost than data lakes and require more time to manage.
|
Typically more expensive due to their size.
|
|
Data governance
|
Easier because data is already partitioned.
|
Requires strict governance rules and systems to access data.
|
More resources:
- Compare data warehouse vs data lake.
- Learn more about data lakes.
- Get the cloud data lake comparison guide.
3 Main Types
Data marts can be established in three ways: using a dependent approach where the mart(s) are created from an existing data warehouse, an independent approach where data is extracted and processed from its sources and loaded directly into the mart, and a hybrid approach where data from an existing data warehouse is combined with data from other sources.
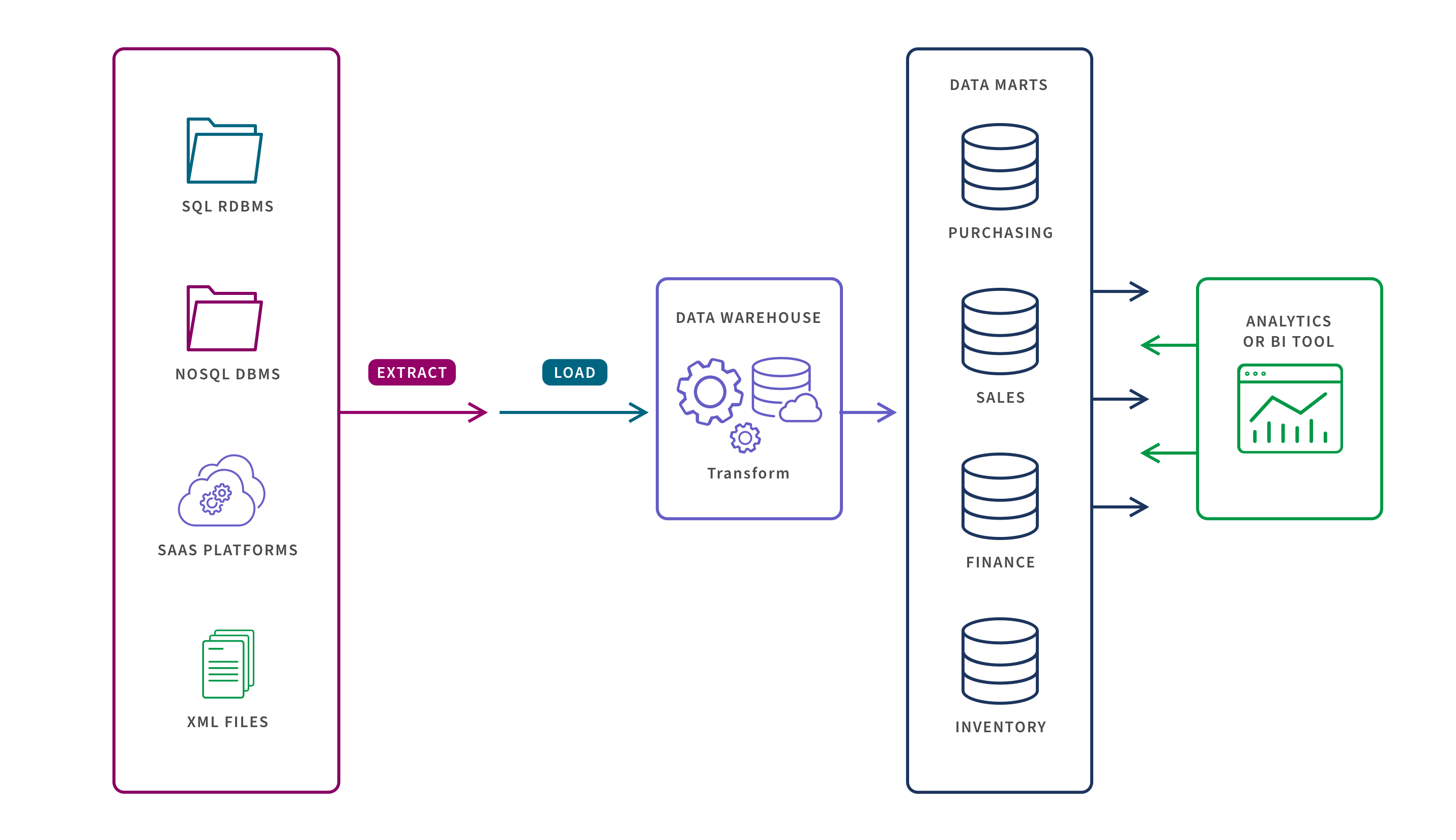
1. Dependent
Also known as top-down approach, dependent data marts draw data directly from a single, existing enterprise data warehouse. This offers centralization in that the data warehouse stores the granular data and is the single point of reference for all dependent repositories. Also, note in the data mart example below how data pipelines are shifting from ETL to ELT (Extract, Load, and Transform), streaming and API.
The marts are partitioned segments of the data warehouse and you extract well-defined subsets of the data warehouse data as needed for analysis. These subsets can be a logical view where virtual tables are logically separated, but not physically separated from the data warehouse, or the subsets can be stored in physically separate repositories from the data warehouse. You might want to physically separate the data for security or performance reasons.
You can choose to limit users access to only the data mart or allow them to access both the data warehouse and the mart. If you’re allowing access to both, be sure to have rigorous data governance practices to maintain data integrity.
2. Independent
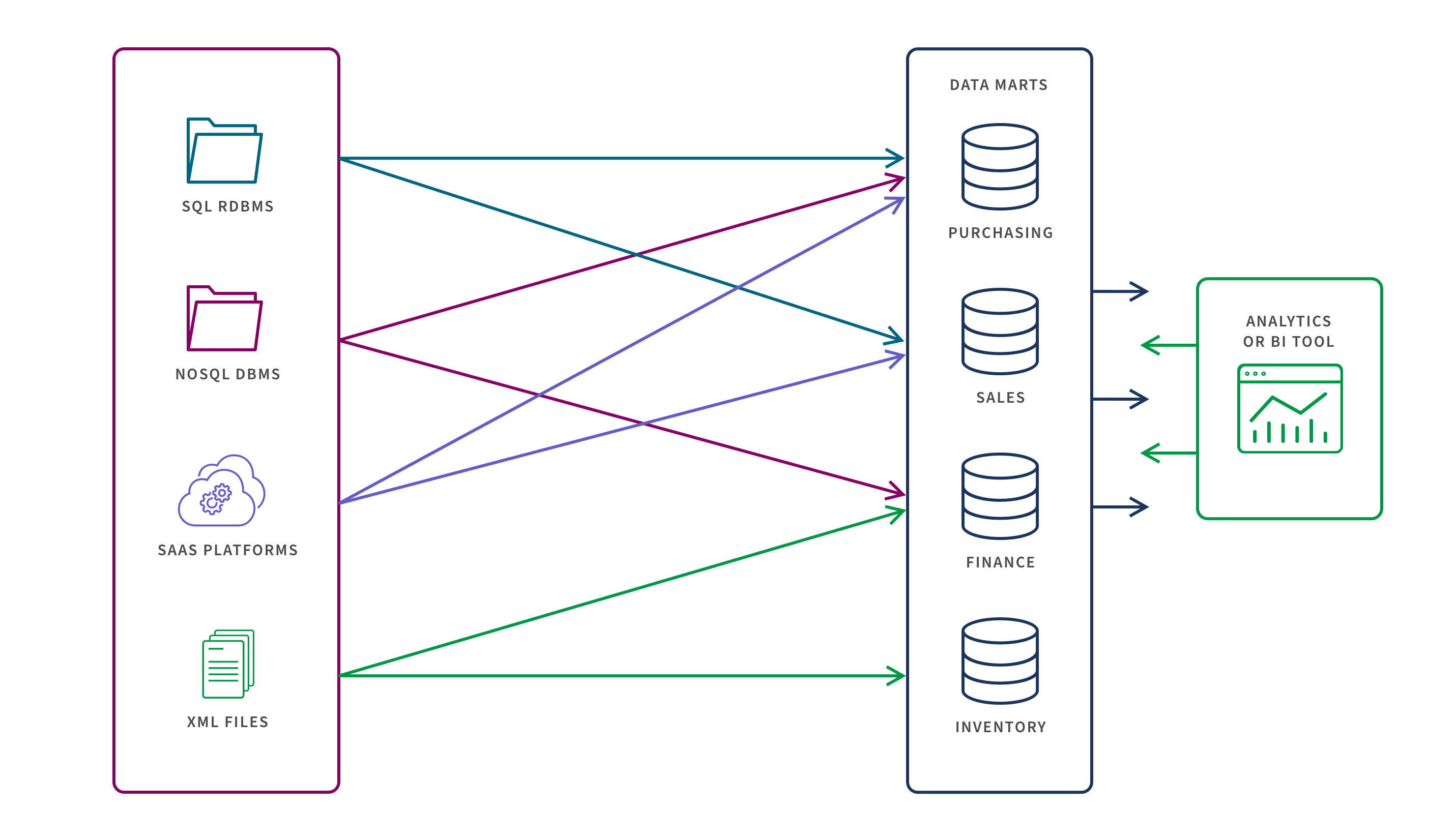
As their name suggests, independent data marts are stand-alone repositories which do not rely on your data warehouse or other marts. Instead, the data necessary for the specific subject or business function is extracted from the appropriate internal and/or external sources, transformed, and then loaded to the mart. Independent data marts are relatively easy to set up and are well-suited for short-term projects or to support small groups in your organization. However, managing them can be complex as you need to maintain data integrity between systems and ETL pipelines for each system. Plus, you lose the benefit of having a single source of truth in a centralized warehouse.
3. Hybrid
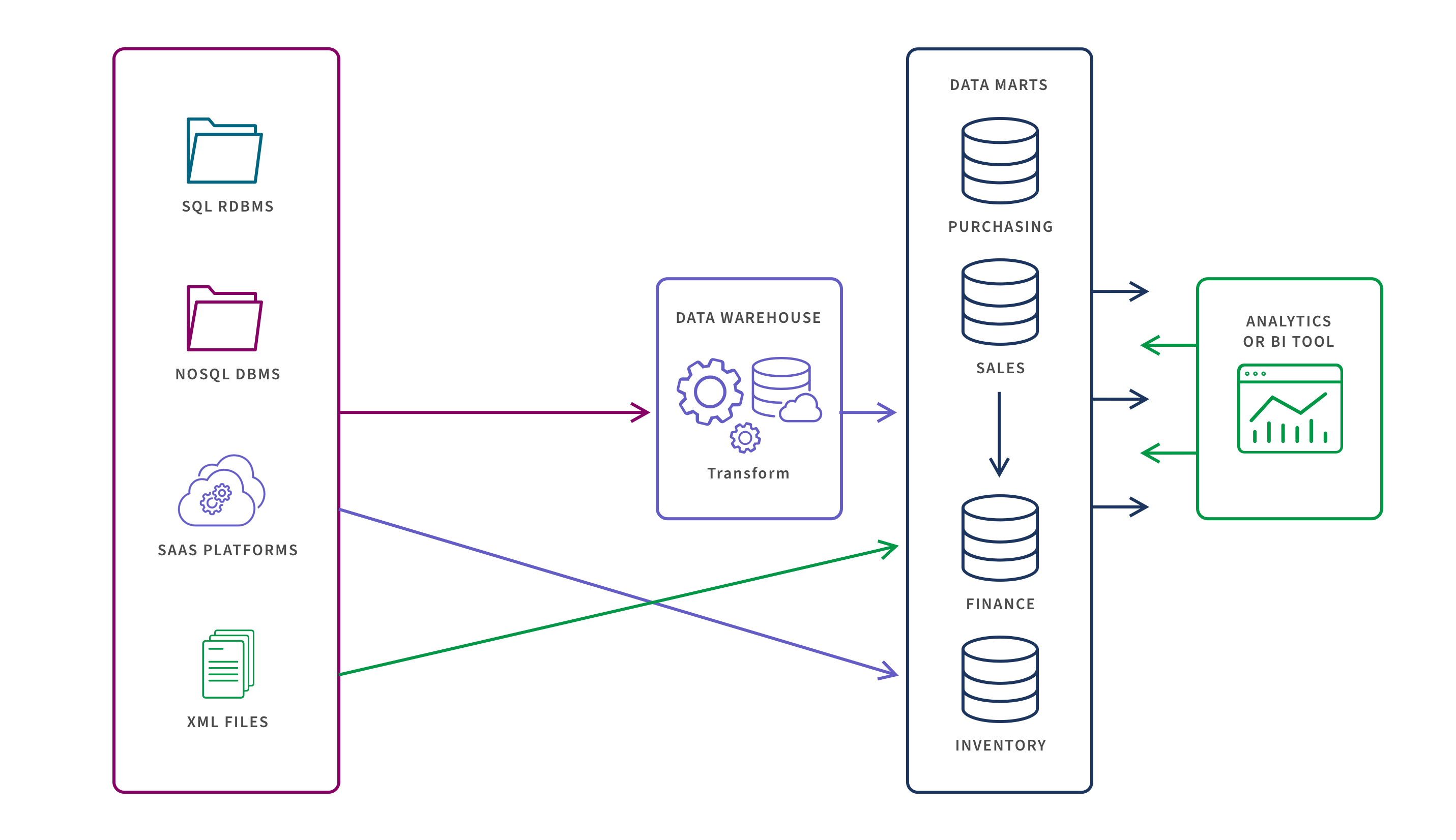
As shown in this data mart example, hybrid data marts combine data from both your data warehouse and your operational source systems such as SaaS applications, SQL databases and flat files. The benefit of this approach is that it gives you both access to cleansed data from the warehouse and the ability to quickly add new sources on an ad hoc basis such as when a new geographic region is added.
Cloud Data Marts
Modern data warehouses and marts are now typically hosted in the cloud. Historically, they were hosted on-premises which required experienced employees to oversee, manually upgrade, and troubleshoot issues. But cloud data warehouse and mart systems are continually evolving with the cloud architectures to support today’s larger datasets and the need to support real-time analytics and machine learning projects.
A cloud-based data mart is more cost-effective than on-premises in that you don’t need to buy new hardware or hire a dedicated team of staff to manage it. Plus it offers immediate and essentially unlimited storage, and is easy to scale as your storage needs grow.
Comparison Guide: Top Cloud Data Warehouses
Download the eBook to see a side-by-side comparison of the leading cloud data warehouse vendors.
Key Challenges
The key steps and challenges of creating and maintaining data marts include:
- Designing and building the mart.
- Loading source data into the data warehouse and mart.
- Keeping the data in the warehouse and the mart in sync with the continuously changing source database systems.
- Delivering in an agile way to keep pace with constantly changing business and analytical requirements.
The foundation of your data mart is typically your data warehouse. Modern data warehouse automation allows you to create data models, add new sources, and provision new marts without writing any SQL code. This minimizes your reliance on resource-constrained ETL developers and database administrators.
DataOps for Analytics
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.
-

Real-Time Data Streaming (CDC)
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution. -

Agile Data Warehouse Automation
Quickly design, build, deploy and manage purpose-built cloud data warehouses without manual coding. -

Managed Data Lake Creation
Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes. -
Enterprise Data Catalog
Enable analytics across your enterprise with a single, self-service data catalog.