Streaming Data
What it is, how it works, examples and best practices. This guide provides practical advice to help you understand and manage streaming data.
What is Streaming Data?
Streaming data refers to data which is continuously flowing from a source system to a target. It is usually generated simultaneously and at high speed by many data sources, which can include applications, IoT sensors, log files, and servers.
Streaming data architecture allows you to consume, store, enrich, and analyze this flowing data in real-time as it is generated. Real-time analytics gives you deeper insights into your business and customer activity and lets you quickly react to changing conditions. These in-the-moment insights can help you respond faster than your competitors to market events and customer issues.
Benefits of Streaming Data
Traditional data pipelines extract, transform, and load data before it can be acted upon. But given the wide variety of sources and the scale and velocity by which the data is generated today, traditional data pipelines are not able to keep up for near real-time or real-time processing.
If your organization deals with big data and produces a steady flow of real-time data, a robust streaming data process will allow you to respond to situations faster. Ultimately, this can help you:
- Increase your customer satisfaction
- Make your company more competitive
- Reduce your infrastructure expenses
- Reduce fraud and other losses
Below are the specific features and benefits which ladder up these higher-level outcomes.
Competitiveness and customer satisfaction. Stream processing enables applications such as modern BI tools to automatically produce reports, alarms and other actions in response to the data, such as when KPIs hit thresholds. These tools can also analyze the data, often using machine learning algorithms, and provide interactive visualizations to deliver you real-time insights. These in-the-moment insights can help you respond faster than your competitors to market events and customer issues.
Reduce your infrastructure expenses. Traditional data processing typically involves storing massive volumes of data in data warehouses or data lakes. In event stream processing, data is typically stored in lower volumes and therefore you enjoy lower storage and hardware hardware costs. Plus, data streams allow you to better monitor and report on your IT systems, helping you troubleshoot servers, systems, and devices.
Reduce Fraud and Other Losses. Being able to monitor every aspect of your business in real-time keeps you aware of issues which can quickly result in significant losses, such as fraud, security breaches, inventory outages, and production issues. Real-time data streaming lets you respond quickly to, and even prevent, these issues before they escalate.
Examples of Streaming Data
The most common use cases for data streaming are streaming media, stock trading, and real-time analytics. However, data stream processing is broadly applied in nearly every industry today. This is due to the continuing rise of big data, the Internet of Things (IoT), real-time applications, and customer expectations for personalized recommendations and immediate response.
Streaming data is critical for any applications which depend on in-the-moment information to support the following use cases:
- Streaming media
- Stock trading
- Real-time analytics
- Fraud detection
- IT monitoring
- Instant messaging
- Geolocation
- Inventory control
- Social media feeds
- Multiplayer video games
- Ride-sharing
Other examples of applying real-time data streaming include:
- Delivering a seamless, up-to-date customer experience across devices.
- Monitoring equipment and scheduling service or ordering new parts when problems are detected.
- Optimizing online content and promotional offers based on each user’s profile.
How Streaming Data Works
Let’s start with an analogy to help frame the concept before we dive into the details. One way to think of streaming data is that it’s like when radio stations constantly broadcast on particular frequencies. (These frequencies are like data topics and you won’t consume them until you turn your processor on to them.) When you tune your radio to a given frequency, your radio picks it up and processes it to become audio you can understand. You want your radio to be fast enough to keep up with the broadcast and if you want a copy of the music you have to record it, because once it’s broadcast, it’s gone.
Two primary layers are needed to process streaming data when using streaming systems like Apache Kafka, Confluent, Google Pub Sub, Amazon Kinesis, and Azure Event Hubs:
- Storage. This layer should enable low cost, quick, replayable reads and writes of large data streams by supporting strong consistency and record ordering.
- Processing. This layer consumes and runs computations on data from the storage layer. It also directs the storage layer to remove data no longer needed.
There’s a broader cloud architecture needed to execute streaming data to its fullest potential. Stream processing systems like Apache Kafka can consume, store, enrich, and analyze data in motion. And, a number of cloud service companies offer the capability for you to build an “off-the-shelf” data stream. However, these options may not meet your requirements or you may face challenges working with your legacy databases or systems. The good news is that there is a robust ecosystem of tools you can leverage, some of them open source, to build your own “bespoke” data stream.
How to build your own data stream. Here we describe how streaming data works and describe the data streaming technologies for each of the four key steps to building your own data stream.
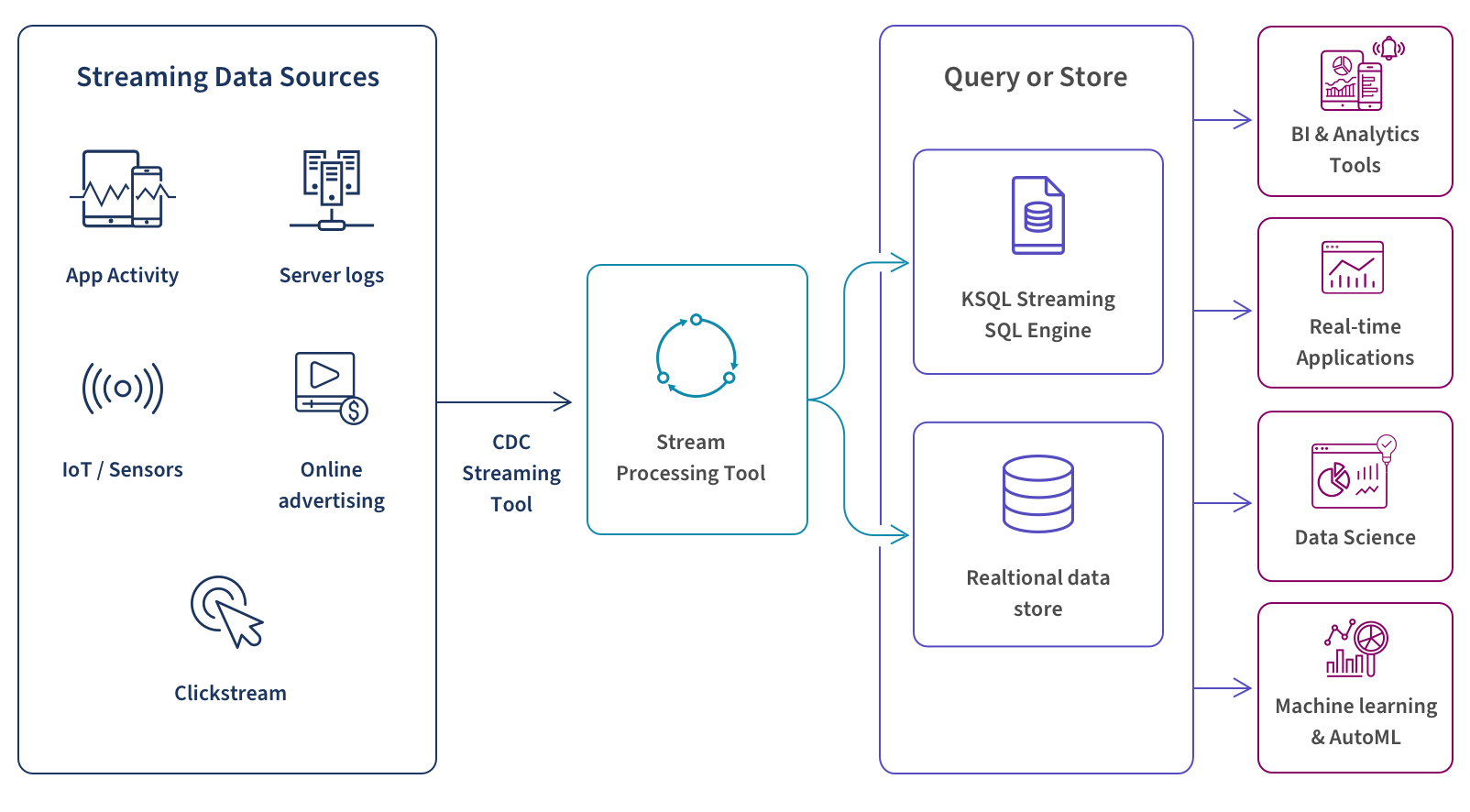
1. Aggregate all your data sources using a CDC streaming tool from relational databases or transactional systems which may be located on-premises or in the cloud. You will then connect these sources to a stream processor.
2. Build a stream processor using a tool such as Apache Kafka or Amazon Kinesis. The data will typically be processed sequentially and incrementally on a record-by-record basis but it can also be processed over sliding time windows.
Your stream processor should:
- Be scalabile, because data volume can vary greatly over time.
- Be fast, because data can quickly lose its relevance and because data flows continuously, so you can’t go back and get any missed data due to latency.
- Be fault tolerant, because data never stops flowing from many sources and in a variety of formats.
- Be integrated, because the data should be immediately passed to downstream applications for presentation or triggered actions.
3. Query or store the streaming data. Leading tools to do this include Google BigQuery, Snowflake, Amazon Kinesis Data Analytics, and Dataflow. These tools can perform a broad range of analytics such as filtering, aggregating, correlating, and sampling.
There are two approaches to do this:
- Query the data stream itself as it’s streaming using KSQL (now ksqlDB), a streaming SQL engine for Apache Kafka. KSQL provides an interactive SQL interface for you to process data in real time in Kafka without writing code. It supports stream processing operations such as joins, aggregations, sessionization, and windowing.
- Store your streamed data. In this more traditional approach, you store the message in a database or data warehouse and query after you’ve received and stored it. Most companies choose to keep all their data given that the cost of storage is low. Leading options for storing streaming data include Amazon S3, Amazon Redshift, and Google Storage.
4. Output for analysis, alerts, real-time applications, data science, and machine learning or AutoML. Once the streaming data has passed through the query or store phase, it can output for multiple use cases:
- The best BI and analytics tools support data stream integration for a variety of streaming analytics use cases such as powering interactive data visualizations and dashboards which alert you and help you respond to changes in KPIs and metrics. These real-time alerts are especially helpful in detecting fraud.
- Streaming data can also trigger events in an application and/or system such as an automated trading system to process a stock trade based on predefined rules.
- Data scientists can apply algorithms in-stream instead of waiting for data to reside in a database. This allows you to query and create visualizations of real-time data.
- Machine learning and AutoML (automated machine learning) models can benefit from incremental learning Python libraries such as Creme to stream over a dataset in sequential order and interleave prediction and learning steps.
Batch vs Real-Time Data Processing
Traditional batch processing cannot keep up with today's complex, fast-moving data environment. Still, many organizations use both a real-time layer and a batch layer to cover the spectrum of their data processing needs.
Let’s take a side-by-side look at batch vs real-time data processing, and how they can work in tandem to provide a holistic data processing solution for your business.
| Batch Processing | Real-Time Stream Processing | |
|---|---|---|
|
Data Type
|
Static, historical data.
|
Dynamic, time-sensitive data.
|
|
Data Ingestion
|
Loaded as batches of large data sets.
|
Ingests a continual sequence of individual records (or micro batches).
|
|
Query Scope
|
Queries the entire dataset.
|
Queries only the most recent data record or within a rolling time window.
|
|
Processing
|
Processes the entire dataset.
|
Processes only the most recent data record or within a rolling time window.
|
|
Latency
|
Can be minutes to hours.
|
Typically milliseconds.
|
|
Data Analysis
|
Deep analysis using sophisticated analytics.
|
Response functions, rolling calculations, and aggregates. (Active Intelligence brings more capabilities)
|
Challenges for Streaming Data
The challenges associated with data streaming arise from the character of the stream data itself. As stated above, it flows continuously in real-time, at high velocity and high volume. It’s also often volatile, heterogeneous and incomplete. This results in the following challenges:
- Scalability. Data volume can vary greatly over time and spike quickly. This is why it’s a good idea to store your data in a cloud data warehouse.
- Durability and consistency. At any particular moment, the data read could already be modified and stale in another data system. This is why it’s critical to have solid data governance and data lineage tools and processes in place.
- Ordering. It’s important to know the sequence of data in the data stream to resolve discrepancies and support applications.
- Fault Tolerance. The data never stops flowing and your system needs to prevent disruptions from a single point of failure while managing data flows from many sources and in a variety of formats.
- Latency. Streaming data can quickly lose its relevance. Plus the data flows continuously, so you can’t go back and get any missed data.
DataOps for Analytics
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.
-

Real-Time Data Streaming (CDC)
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution. -

Agile Data Warehouse Automation
Quickly design, build, deploy and manage purpose-built cloud data warehouses without manual coding. -

Managed Data Lake Creation
Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes. -
Enterprise Data Catalog
Enable analytics across your enterprise with a single, self-service data catalog.