What is ETL?
What it is, why it matters and use cases. This guide provides definitions, use case examples and practical advice to help you understand ETL.
What is ETL?
ETL stands for “Extract, Transform, and Load” and describes the set of processes to extract data from one system, transform it, and load it into a target repository. An ETL pipeline is a traditional type of data pipeline for cleaning, enriching, and transforming data from a variety of sources before integrating it for use in data analytics, business intelligence and data science.
Key Benefits
Using an ETL pipeline to transform raw data to match the target system, allows for systematic and accurate data analysis to take place in the target repository. Specifically, the key benefits are:
- More stable and faster data analysis on a single, pre-defined use case. This is because the data set has already been structured and transformed.
- Easier compliance with GDPR, HIPAA, and CCPA standards. This is because users can omit any sensitive data prior to loading in the target system.
- Identify and capture changes made to a database via the change data capture (CDC) process or technology. These changes can then be applied to another data repository or made available in a format consumable by ETL, EAI, or other types of data integration tools.
ETL vs ELT
The key difference between the two processes is when the transformation of the data occurs. Many organizations use both processes to cover their wide range of data pipeline needs.
The ETL process is most appropriate for small data sets which require complex transformations. For larger, unstructured data sets and when timeliness is important, the ELT process is more appropriate.
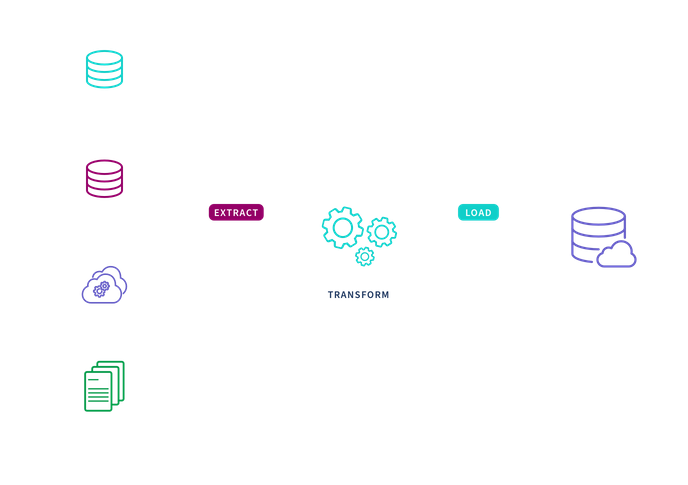
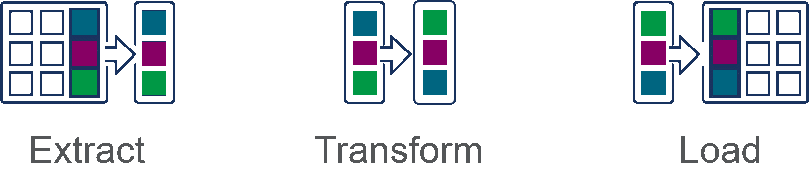
Extract > Transform > Load (ETL)
In the ETL process, transformation is performed in a staging area outside of the data warehouse and before loading it into the data warehouse. The entire data set must be transformed before loading, so transforming large data sets can take a lot of time up front. The benefit is that analysis can take place immediately once the data is loaded. This is why this process is appropriate for small data sets which require complex transformations.
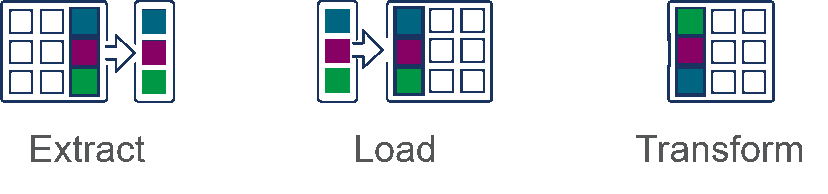
Extract > Load > Transform (ELT)
In the ELT process, data transformation is performed on an as-needed basis within the target system. This means that the ELT process takes less time. But if there is not sufficient processing power in the cloud solution, transformation can slow down the querying and analysis processes. This is why the ELT process is more appropriate for larger, structured and unstructured data sets and when timeliness is important.
More resources:
- Learn more about the ELT process
- See a side-by-side review of 10 key areas in the ETL vs ELT Comparison Matrix.
- Watch the brief video below to learn why the market is shifting toward ELT.

ETL or ELT?
Times are changing. Download the eBook to learn how to choose the right approach for your business, what ELT delivers that ETL can’t, and how to build a real-time data pipeline with ELT.
How ETL Works
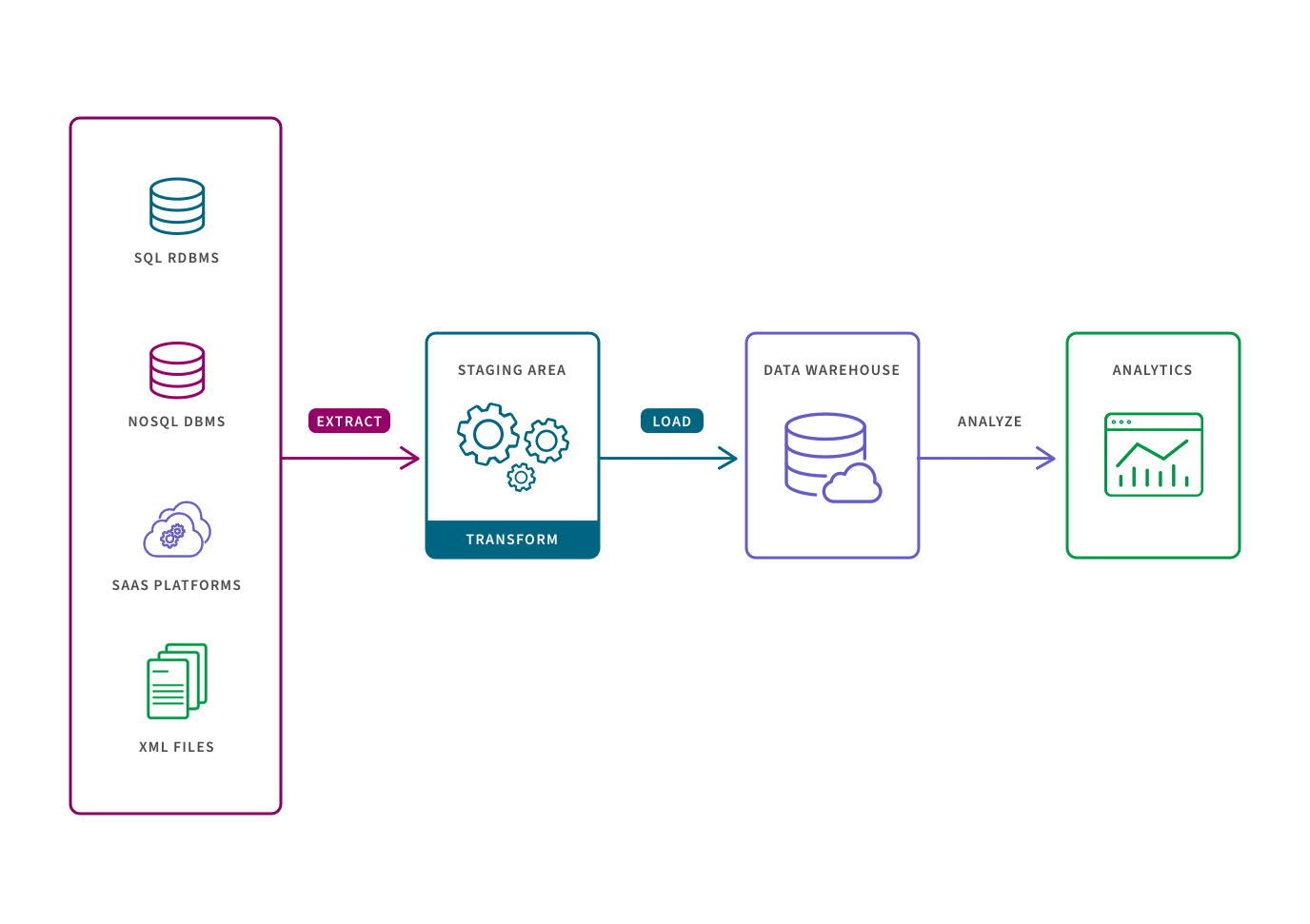
The traditional ETL process is broken out as follows:
- Extract refers to pulling a predetermined subset of data from a source such as an SQL or NoSQL database, a cloud platform or an XML file.
- Transform refers to converting the structure or format of a data set to match that of the target system. This is typically performed in a staging area in ways such as data mapping, applying concatenations or calculations. Transforming the data before it is loaded is necessary to deal with the constraints of traditional data warehouses.
- Load refers to the process of placing the data into the target system, typically a data warehouse, where it is ready to be analyzed by BI tools or data analytics tools.
ETL Use Cases
The ETL process helps eliminate data errors, bottlenecks, and latency to provide for a smooth flow of data from one system to the other. Here are some of the key use cases:
- Migrating data from a legacy system to a new repository.
- Centralizing data sources to gain a consolidated version of the data.
- Enriching data in one system with data from another system.
- Providing a stable dataset for data analytics tools to quickly access a single, pre-defined analytics use case given that the data set has already been structured and transformed.
- Complying with GDPR, HIPAA, and CCPA standards.
ETL Tools
There are four primary types of ETL tools:
Batch Processing: Traditionally, on-premises batch processing was the primary ETL process. In the past, processing large data sets impacted an organization’s computing power and so these processes were performed in batches during off-hours. Today’s ETL tools can still do batch processing, but since they’re often cloud-based, they’re less constrained in terms of when and how quickly the processing occurs.
Cloud-Native. Cloud-native ETL tools can extract and load data from sources directly into a cloud data warehouse. They then use the power and scale of the cloud to transform the data.
Open Source. Open source tools such as Apache Kafka offer a low-cost alternative to commercial ETL tools. However, some open source tools only support one stage of the process, such as extracting data, and some are not designed to handle data complexities or change data capture (CDC). Plus, it can be tough to get support for open source tools.
Real-Time. Today’s business demands real-time access to data. This requires organizations to process data in real time, with a distributed model and streaming capabilities. Streaming ETL tools, both commercial and open source, offer this capability.
Learn more about ETL tools and different approaches to solve this challenge:

ETL Tools Alternative: Data Warehouse Automation
Building and maintaining a data warehouse can require hundreds or thousands of ETL tool programs. As a result, building data warehouses with ETL tools can be time-consuming, cumbersome, and error-prone — introducing delays and unnecessary risk into BI projects that require the most up-to-date data, and the agility to react quickly to changing business demands.
New, agile data warehouse automation and transformation platforms eliminate the need for conventional ETL tools by automating repetitive, labor-intensive tasks associated with ETL integration and data warehousing.
ETL automation frees you from error-prone manual coding and it automates the entire data warehousing lifecycle from design and development to impact analysis and change management. ETL automation tools automatically generate the ETL commands, data warehouse structures, and documentation necessary for designing, building, and maintaining your data warehouse program, helping you save time, reduce cost, and reduce project risk.
Seamless integration with a real-time event capture and data integration solution enables real-time ETL by combining real-time source data integration with automated ETL generation—and supports a wide ecosystem of heterogeneous data sources including relational, legacy, and NoSQL data stores.
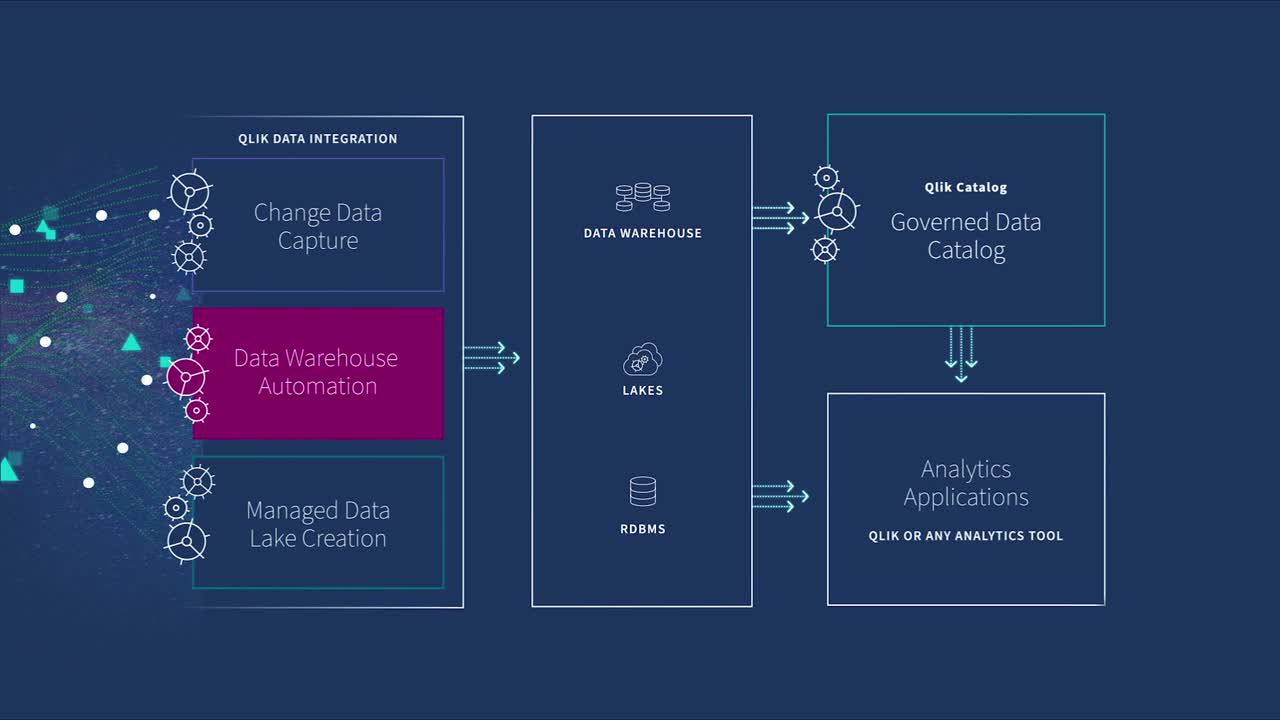
DataOps for Analytics
Modern data integration delivers real-time, analytics-ready and actionable data to any analytics environment, from Qlik to Tableau, Power BI and beyond.
-

Real-Time Data Streaming (CDC)
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution. -

Agile Data Warehouse Automation
Quickly design, build, deploy and manage purpose-built cloud data warehouses without manual coding. -

Managed Data Lake Creation
Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes. -
Enterprise Data Catalog
Enable analytics across your enterprise with a single, self-service data catalog.